ApasaraCache
https://github.com/alibaba/ApsaraCache
简介
ApsaraCache(飞天缓存)是云数据库 Redis 版所使用的 Redis 分支
拥有很多成功的客户案例,其中既有视频直播行业的秒拍、一直播、映客、中国网络电视台;也有游戏行业的陌陌游戏、龙渊网络、中情龙图、畅游;同时还有民生类的新闻如今日头条、交通如高德导航、金融如蚂蚁金服、其他如大疆创新,可以说,应用范围和场景非常广泛。
优势:
- 兼容Memcached协议,提供持久化,双机热备能力,数据更稳定可靠;
- 短连接场景下性能提升30%以上,对于PHP等短连接应用居多的用户效果提升更为明显;
- 解决了原生内核在弱网条件下容易复制中断导致的全量同步问题;
- 避免AOF Rewrite频繁造成的主机稳定性瓶颈,且能精确到秒级的按时间点恢复;
- 增加了热升级的功能,能够在3ms内完成一个实例的热更新,解决了内核频繁升级对用户带来的影响;
- 对实例的可用性进行检测,避免 Redis单线程阻塞,同时可对磁盘进行探测解决磁盘提前反馈切换。
原理
- Redis 服务器每秒至少可以同时为 3,000 ~ 10,000 个用户获取信息流消息
- Redis keys单个instance上限有2的23次方,250,000,000个key
Redis持久化
http://www.jianshu.com/p/2f14bc570563?from=jiantop.com
Redis提供了将数据定期自动持久化至硬盘的能力,包括RDB和AOF两种方案,两种方案分别有其长处和短板,可以配合起来同时运行,确保数据的稳定性。
Redis的数据持久化机制是可以关闭的。如果你只把Redis作为缓存服务使用,Redis中存储的所有数据都不是该数据的主体而仅仅是同步过来的备份,那么可以关闭Redis的数据持久化机制。
RDB
采用RDB持久方式,Redis会定期保存数据快照至一个rbd文件中,并在启动时自动加载rdb文件,恢复之前保存的数据。可以在配置文件中配置Redis进行快照保存的时机:
save [seconds] [changes]意为在[seconds]秒内如果发生了[changes]次数据修改,则进行一次RDB快照保存,例如
save 60 100会让Redis每60秒检查一次数据变更情况,如果发生了100次或以上的数据变更,则进行RDB快照保存。
可以配置多条save指令,让Redis执行多级的快照保存策略。
Redis默认开启RDB快照,默认的RDB策略如下:save 900 1 save 300 10 save 60 10000也可以通过BGSAVE命令手工触发RDB快照保存。
RDB的优点:
* 对性能影响最小。如前文所述,Redis在保存RDB快照时会fork出子进程进行,几乎不影响Redis处理客户端请求的效率。(但是如果数据量比较大,那么会造成比较大的延迟) * 每次快照会生成一个完整的数据快照文件,所以可以辅以其他手段保存多个时间点的快照(例如把每天0点的快照备份至其他存储媒介中),作为非常可靠的灾难恢复手段。 * 使用RDB文件进行数据恢复比使用AOF要快很多。RDB的缺点:
* 快照是定期生成的,所以在Redis crash时或多或少会丢失一部分数据。 * 如果数据集非常大且CPU不够强(比如单核CPU),Redis在fork子进程时可能会消耗相对较长的时间(长至1秒),影响这期间的客户端请求。AOF
采用AOF持久方式时,Redis会把每一个写请求都记录在一个日志文件里。在Redis重启时,会把AOF文件中记录的所有写操作顺序执行一遍,确保数据恢复到最新。
AOF默认是关闭的,如要开启,进行如下配置:
appendonly yesAOF提供了三种fsync配置,always/everysec/no,通过配置项[appendfsync]指定:
appendfsync no:不进行fsync,将flush文件的时机交给OS决定,速度最快 appendfsync always:每写入一条日志就进行一次fsync操作,数据安全性最高,但速度最慢 appendfsync everysec:折中的做法,交由后台线程每秒fsync一次aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。
随着AOF不断地记录写操作日志,必定会出现一些无用的日志,例如某个时间点执行了命令SET key1 “abc”,在之后某个时间点又执行了SET key1 “bcd”,那么第一条命令很显然是没有用的。大量的无用日志会让AOF文件过大,也会让数据恢复的时间过长。
所以Redis提供了AOF rewrite功能,可以重写AOF文件,只保留能够把数据恢复到最新状态的最小写操作集(我理解的,比如同一个key,set多次,只最后一次的。)。
AOF rewrite可以通过BGREWRITEAOF命令触发,也可以配置Redis定期自动进行:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
上面两行配置的含义是,Redis在每次AOF rewrite时,会记录完成rewrite后的AOF日志大小,当AOF日志大小在该基础上增长了100%后,自动进行AOF rewrite。同时如果增长的大小没有达到64mb,则不会进行rewrite。
AOF的优点:
- 最安全,在启用appendfsync always时,任何已写入的数据都不会丢失,使用在启用appendfsync everysec也至多只会丢失1秒的数据。
- AOF文件在发生断电等问题时也不会损坏,即使出现了某条日志只写入了一半的情况,也可以使用redis-check-aof工具轻松修复。
- AOF文件易读,可修改,在进行了某些错误的数据清除操作后,只要AOF文件没有rewrite,就可以把AOF文件备份出来,把错误的命令删除,然后恢复数据。
AOF的缺点:
- AOF文件通常比RDB文件更大
- 性能消耗比RDB高
- 数据恢复速度比RDB慢
Redis实战
当redis中存储的数据量只有几个G的时候,使用快照来保存数据是没有问题的。redis会创建子进程并将数据保存到硬盘里面,生成快照的时间很短
但是如果redis占用的内存越来越大,BGSAVE占用的时间会很长,导致系统长时间的停顿。
* 所以最好的方式是,在凌晨发送SAVA来执行快照 * 然后其他时间用AOF来保证持久性。快照保存过程
1.redis调用fork,现在有了子进程和父进程。 2. 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本(注:应该是把修改前的段创建副本给子进程),而不是写共享的页面。所以子进程的地址空间内的数 据是fork时刻整个数据库的一个快照。 3.当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。
另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
应用
Redis 安装
yum install redis
find / -name *redis*
redis-server /etc/redis.conf
CentOS 6.5 下安装 Redis 2.8.7
安装
wget http://download.redis.io/redis-stable.tar.gz tar xvzf redis-stable.tar.gz cd redis-stable make
前面3步应该没有问题,主要的问题是执行make的时候,出现了异常。
异常一:
make[2]: cc: Command not found
异常原因:没有安装gcc
解决方案:yum install gcc-c++
异常二:
zmalloc.h:51:31: error: jemalloc/jemalloc.h: No such file or directory
异常原因:一些编译依赖或原来编译遗留出现的问题
解决方案:make distclean。清理一下,然后再make。
- 在make成功以后,需要make test。
在make test出现异常。
异常一:
couldn’t execute “tclsh8.5”: no such file or directory
异常原因:没有安装tcl
解决方案:yum install -y tcl。
在make成功以后,会在src目录下多出一些可执行文件:redis-server,redis-cli等等。
方便期间用cp命令复制到usr目录下运行。
cp redis-server /usr/local/bin/ cp redis-cli /usr/local/bin/ cp redis-sentinel /usr/local/bin/然后新建目录,存放配置文件
mkdir /etc/redis mkdir /var/redis mkdir /var/redis/log mkdir /var/redis/run mkdir /var/redis/6379在redis解压根目录中找到配置文件模板,复制到如下位置。
cp redis.conf /etc/redis/6379.conf通过vim命令修改
daemonize yes pidfile /var/redis/run/redis_6379.pid logfile /var/redis/log/redis_6379.log dir /var/redis/6379最后运行redis:
redis-server /etc/redis/6379.conf关闭redis
redis-cli shutdown修改iptables,打开6379接口
-A INPUT -m state --state NEW -m tcp -p tcp --dport 6379 -j ACCEPT -A INPUT -m state --state NEW -m tcp -p tcp --dport 26379 -j ACCEPT /etc/init.d/iptables restart客户端连接
redis-cli
操作Redis
简单粗暴的Redis数据备份和恢复方法
在CentOS上找dump文件位置
vi /etc/redis.conf dbfilename dump.rdb dir /var/lib/redis说明文件在
/var/lib/redis/dump.rdb拷贝服务器上的dump.rdb
重启Redis
插入数据
redis 127.0.0.1:6379> set name wwl OK
设置一个key-value对。
查询数据
redis 127.0.0.1:6379> get name "wwl"
取出key所对应的value。
删除键值
redis 127.0.0.1:6379> del name
删除这个key及对应的value。
验证键是否存在
redis 127.0.0.1:6379> exists name (integer) 0
其中0,代表此key不存在;1代表存在。
删除当前数据库中的所有Key
flushdb删除所有数据库中的key
flushall查看redis的信息
redis-cli -h 192.168.9.18 info Replication配置senital.conf文件
cp sentinel.conf /etc/redis/sentinel.conf修改
#sentinel监控的redis的名字、IP和端口,最后一个数字是sentinel做决策的时候需要投赞同票的最少的sentinel的数量。 sentinel monitor mymaster 192.168.9.18 6379 1启动sentinel
redis-sentinel /etc/redis/sentinel.conf也可以单独指定端口,这里启动两个哨兵
redis-server /etc/redis/sentinel.conf --sentinel --port 26379 redis-server /etc/redis/sentinel.conf --sentinel --port 36379在哨兵26379中查看当前主服务器相关信息:
redis-cli -p 26379 127.0.0.1:26379> sentinel masters
集群缓存服务器
https://www.cnblogs.com/wuxl360/p/5920330.html
redis是3.0后增加的集群功能,非常强大
集群中应该至少有三个节点,每个节点有一备份节点。这样算下来至少需要6台服务器
安装环境与版本
用两台虚拟机模拟6个节点,一台机器3个节点,创建出3 master、3 salve 环境。
redis 采用 redis-3.2.4 版本。
两台虚拟机都是 CentOS ,一台 CentOS6.5 (IP:192.168.31.245),一台 CentOS7(IP:192.168.31.210) 。
安装过程
下载并解压
cd /root/software wget http://download.redis.io/releases/redis-3.2.4.tar.gz tar -zxvf redis-3.2.4.tar.gz编译安装
cd redis-3.2.4 make && make install将 redis-trib.rb 复制到 /usr/local/bin 目录下
cd src cp redis-trib.rb /usr/local/bin/
创建 Redis 节点
首先在 192.168.31.245 机器上 /root/software/redis-3.2.4 目录下创建 redis_cluster 目录;
mkdir redis_cluster在 redis_cluster 目录下,创建名为7000、7001、7002的目录,并将 redis.conf 拷贝到这三个目录中
mkdir 7000 7001 7002<br>cp redis.conf redis_cluster/7000 cp redis.conf redis_cluster/7001 cp redis.conf redis_cluster/7002分别修改这三个配置文件,修改如下内容
port 7000 //端口7000,7002,7003 bind 本机ip //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群 daemonize yes //redis后台运行 pidfile /var/run/redis_7000.pid //pidfile文件对应7000,7001,7002 cluster-enabled yes //开启集群 把注释#去掉 cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002 cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置 appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志接着在另外一台机器上(192.168.31.210),的操作重复以上三步,只是把目录改为7003、7004、7005,对应的配置文件也按照这个规则修改即可
启动各个节点
第一台机器上执行 redis-server redis_cluster/7000/redis.conf redis-server redis_cluster/7001/redis.conf redis-server redis_cluster/7002/redis.conf 另外一台机器上执行 redis-server redis_cluster/7003/redis.conf redis-server redis_cluster/7004/redis.conf redis-server redis_cluster/7005/redis.conf检查 redis 启动情况
##一台机器<br>ps -ef | grep redis root 61020 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7000 [cluster] root 61024 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7001 [cluster] root 61029 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7002 [cluster] netstat -tnlp | grep redis tcp 0 0 127.0.0.1:17000 0.0.0.0:* LISTEN 61020/redis-server tcp 0 0 127.0.0.1:17001 0.0.0.0:* LISTEN 61024/redis-server tcp 0 0 127.0.0.1:17002 0.0.0.0:* LISTEN 61029/redis-server tcp 0 0 127.0.0.1:7000 0.0.0.0:* LISTEN 61020/redis-server tcp 0 0 127.0.0.1:7001 0.0.0.0:* LISTEN 61024/redis-server tcp 0 0 127.0.0.1:7002 0.0.0.0:* LISTEN 61029/redis-server ##另外一台机器 ps -ef | grep redis root 9957 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7003 [cluster] root 9964 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7004 [cluster] root 9971 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7005 [cluster] root 10065 4744 0 02:38 pts/0 00:00:00 grep --color=auto redis netstat -tlnp | grep redis tcp 0 0 127.0.0.1:17003 0.0.0.0:* LISTEN 9957/redis-server 1 tcp 0 0 127.0.0.1:17004 0.0.0.0:* LISTEN 9964/redis-server 1 tcp 0 0 127.0.0.1:17005 0.0.0.0:* LISTEN 9971/redis-server 1 tcp 0 0 127.0.0.1:7003 0.0.0.0:* LISTEN 9957/redis-server 1 tcp 0 0 127.0.0.1:7004 0.0.0.0:* LISTEN 9964/redis-server 1 tcp 0 0 127.0.0.1:7005 0.0.0.0:* LISTEN 9971/redis-server 1创建集群
Redis 官方提供了 redis-trib.rb 这个工具,就在解压目录的 src 目录中,第三步中已将它复制到 /usr/local/bin 目录中,可以直接在命令行中使用了。
这个工具是用 ruby 实现的,所以需要安装 ruby。安装命令如下:
yum -y install ruby ruby-devel rubygems rpm-build gem install redis使用下面这个命令即可完成安装。
redis-trib.rb create --replicas 1 192.168.31.245:7000 192.168.31.245:7001 192.168.31.245:7002 192.168.31.210:7003 192.168.31.210:7004 192.168.31.210:7005会出现如下提示:
Can I set the above configuration?(type 'yes' to accept):输入yes即可
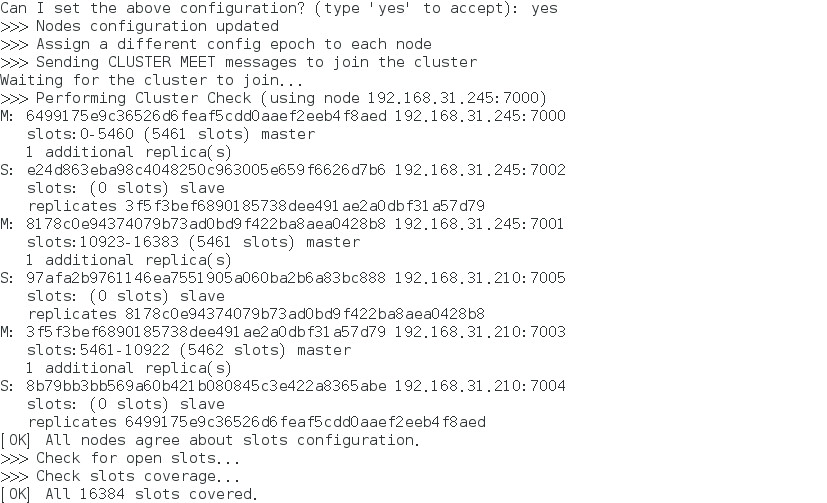
集群验证
在第一台机器上连接集群的7002端口的节点,在另外一台连接7005节点,连接方式为
redis-cli -h 192.168.31.245 -c -p 7002 #加参数 -C 可连接到集群,因为上面 redis.conf 将 bind 改为了ip地址,所以 -h 参数不可以省略。在7005节点执行命令
set hello world然后在另外一台7002端口,查看 key 为 hello 的内容
get hello如看到world,则配置成功
原理
Redis Cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7000端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:
必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。Redis集群网络闪断后如何保证数据一致性
为了避免网络不稳定造成的全量同步修改参数如下:
config set repl-timeout 240 config set repl-backlog-size 67108864repl-timeout
redis里面的repl-timeout参数值也太小也将会导致复制不成功.三种情况认为复制超时:
1)slave角度,如果在repl-timeout时间内没有收到master SYNC传输的rdb snapshot数据, 2)slave角度,在repl-timeout没有收到master发送的数据包或者ping。 3)master角度,在repl-timeout时间没有收到REPCONF ACK确认信息。当redis检测到repl-timeout超时(默认值60s),将会关闭主从之间的连接,redis slave发起重新建立主从连接的请求。
对于内存数据集比较大的系统,可以增大repl-timeout参数。
repl-backlog-size
当主服务器进行命令传播的时候,maser不仅将所有的数据更新命令发送到所有slave的replication buffer,还会写入replication backlog。当断开的slave重新连接上master的时候,slave将会发送psync命令(包含复制的偏移量offset),请求partial resync。如果请求的offset不存在,那么执行全量的sync操作,相当于重新建立主从复制。
实战
Redis 的性能幻想与残酷现实
Redis 的单线程设计机制只能利用一个核,导致单核 CPU 的最大处理能力就是 Redis 单实例处理能力的天花板了。
官方的基准性能测试
测试前提 Redis version 2.4.2 Using the TCP loopback Payload size = 256 bytes 测试结果 SET: 198412.69/s GET: 198019.80/s在局域网环境下只要传输的包不超过一个 MTU (以太网下大约 1500 bytes),那么对于 10、100、1000 bytes 不同包大小的处理吞吐能力实际结果差不多
实际
测试前提 Redis version 2.4.1 Jmeter version 2.4 Network 1000Mb Payload size = 100 bytes 测试结果 SET: 32643.4/s GET: 32478.8/sRedis 还有个 10k 问题,当缓存数据大于 10k(用作静态页面的缓存,就可能超过这个大小)延迟会明显增加,这也是单线程机制带来的问题。
根据数据性质把 Redis 集群分类;我的经验是分三类:cache、buffer 和 db
cache:临时缓存数据,加分片扩容容易,一般无持久化需要。
buffer:用作缓冲区,平滑后端数据库的写操作,根据数据重要性可能有持久化需求。
db:替代数据库的用法,有持久化需求。
规避在单实例上放热点 key。
同一系统下的不同子应用或服务使用的 Redis 也要隔离开
配置slave服务器
只需要在配置文件中加入如下配置
slaveof 192.168.1.1 6379 #指定master的ip和端口
redis 批量导入
cat iqiyi4.cadd | /www/redis/redis-cli -p 6389 -a cxy --pipe
cat iqiyi5.cadd | /www/redis/redis-cli -p 6389 -a cxy --pipe
文件内容如:(注意回车要\r\n,内容要双引号最好)
sadd iqiyi4 "0034-4413-3FAC-895B"
redis只允许内网访问,绑定ip
运行redis的机器只允许其他机器通过内网ip访问redis
打开配置文件.conf
找到bind 项目增加内网ip地址
重新启动redis服务
亿级社交平台
https://www.toutiao.com/i6280284764175860226/
- 添加提供读能力的从服务器
- 只对主服务器进行写入
同时向多个从服务器发送快照的多个副本,可能会将主服务器可用的大部分带宽消耗殆尽
减少主服务器需要传送给从服务器的数据数量,这可以通过构建树状复制中间层来完成
另一个方法就是对网络连接进行压缩,从而减少需要传送的数据量。
一些 Redis 用户就发现使用带压缩的 SSH 隧道(tunnel)进行连接可以明显地降低带宽占用 SSH 默认使用的是 gzip 压缩算法,SSH 提供了配置选项,可以让用户选择指定的压缩级别(具体信息可以参考SSH的文档),它的 1 级压缩在使用之前提到的 2.6GHz 处理器的情况下,可以在复制的初始时候,以每秒 24~52MB 的速度对 Redis 的 RDB 文件进行压缩;并在复制进入持续更新阶段之后,以每秒 60~80MB 的速度对 Redis 的 AOF 文件进行压缩。
扩展写性能和内存容量
随着被缓存的数据越来越多,当数据没办法被存储到单台机器上面的时候,我们就需要想办法把数据分割存储到由多台机器组成的集群里面。
尽可能地减少了需要写入的数据量
- 对自己编写的所有方法进行了检查,尽可能地减少程序需要读取的数据量。
- 将无关的功能迁移至其他服务器。
- 在对 Redis 进行写入之前,尝试在本地内存中对将要写入的数据进行聚合计算,这一做法可以应用于所有分析方法和统计计算方法。
- 使用锁去替换可能会给速度带来限制的 WATCH/MULTI/EXEC 事务,或者使用 Lua 脚本。
在使用 AOF 持久化的情况下,机器的硬盘必须将程序写入的所有数据都存储起来,这需要花费一定的时间。对于 400,000 个短命令来说,硬盘每秒可能只需要写入几 MB 的数据;但是对于 100,000 个长度为 1KB 的命令来说,硬盘每秒将需要写入100MB 的数据。
如果用尽了一切方法降低内存占用并且尽可能地提高性能之后,问题仍然未解决,那么说明我们已经遇到了只使用单台机器带来的瓶颈,是时候将数据分片到多台机器上面了。
工具
redis desktop manager
windows 版的GUI管理工具
360开源的类Redis存储系统:Pika
https://github.com/Qihoo360/pika
重点
Pika 的单线程的性能肯定不如 Redis,Pika 是多线程的结构,因此在线程数比较多的情况下,某些数据结构的性能可以优于 Redis。
Pika 肯定不是完全优于 Redis 的方案,只是在某些场景下面更适合。所以目前公司内部 Redis,Pika 是共同存在的方案。DBA 会根据业务的场景挑选合适的方案。
问题汇总
常见问题
(error) MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk.
原因:
强制关闭Redis快照导致不能持久化。
解决方案:
运行config set stop-writes-on-bgsave-error no 命令后,关闭配置项stop-writes-on-bgsave-error解决该问题。
redis-cli 127.0.0.1:6379> config set stop-writes-on-bgsave-error no OK
Redis 未授权访问缺陷
一个异常的进程占用了将近百分之800(8核)cpu使用率
起因便是redis未授权漏洞造成
漏洞概要
Redis 默认情况下,会绑定在 0.0.0.0:6379,这样将会将Redis服务暴露到公网上,如果在没有开启认证的情况下,可以导致任意用户在可以访问目标服务器的情况下未授权访 问Redis以及读取Redis的数据。攻击者在未授权访问Redis的情况下可以利用Redis的相关方法,可以成功将自己的公钥写入目标服务器的 /root/.ssh 文件夹的authotrized_keys 文件中,进而可以直接登录目标服务器。临时解决方案
配置bind选项, 限定可以连接Redis服务器的IP, 并修改redis的默认端口6379. 配置AUTH, 设置密码, 密码会以明文方式保存在redis配置文件中. 配置rename-command CONFIG "RENAME_CONFIG", 这样即使存在未授权访问, 也能够给攻击者使用config指令加大难度 好消息是Redis作者表示将会开发”real user”,区分普通用户和admin权限,普通用户将会被禁止运行某些命令,如config
- WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
net.core.somaxconn是Linux中的一个kernel参数,表示socket监听(listen)的backlog上限。什么是backlog呢?backlog就是socket的监听队列,当一个请求(request)尚未被处理或建立时,他会进入backlog。而socket server可以一次性处理backlog中的所有请求,处理后的请求不再位于监听队列中。当server处理请求较慢,以至于监听队列被填满后,新来的请求会被拒绝。
命令
1 | # sysctl -a |
a